6 Biggest Lies in Records Management

Here are 6 lies that I bump into every single day that drives me absolutely mad. Strap in, this is a hate article in two parts where I expose the lies and share the truth. I will be going over
1) If Data Governance and Information Governance will ever merge
2) The dreams of a cryptocurrency bro: BlockChain
3) Whether regulations will save our industry
4) The myth of Trash Data in Trash AI out
5) If only people cared about records management
6) Too much data is an excuse
Data Governance and Information Governance will merge
Impossible for these two to merge. The way you manage structured data is the exact opposite of the way you manage unstructured data.
Take your FICO score as an example. There is usually a history of the score. You can delete that
whole history and not lose a single bit of information. It's only your current FICO score that matters.
Quite similarly, you can delete every single transaction from your purchase history and it won't effect how much money you have in the bank.
This purge is frequently done to keep databases efficient, albeit not in banking as much.
Now try deleting every single email except the last one, including the threads. No "oh, I can scroll down to see the past emails" shenanigans. All of it, gone.
Yes, there are parallels. Both can be analyzed with AI now, both have retention schedules, both have regulations. But that's as far as the similarities go.
Those regulations rarely have anything in similar. The way you analyze structured data is nothing like unstructured data. When you actually look at how this data is managed, they couldn't be further apart.
BlockChain
BlockChain came out of cryptocurrencies. The dream was to eliminate all inflation and create an international currency not subject to governments. At some point, the general technology of BlockChain made a break and stopped being just about cryptocurrency, but became the talking point of each vendor.
So, how much of it is true? Are cryptocurrencies really inflation proof and not subject to governments? If they are not, is BlockChain even a useful technology?
Here is how they work. Cryptocurrencies and BlockChain use 3 different technologies.
First is cryptography which is a fancy way to say extremely hard math questions. Each time you want to add an input to the ledger (the cryptocurrency) you need to solve this question.
Second is a BlockChain, more commonly known as a linked list. Basically, every data is connected to the data previously entered and the next data to be entered. When combined with cryptography, this technology ensures that no previous data can be edited.
To better understand how these two combine, here is an example. You start with the initial state. For simplicity sake, let's say there are 2 users. No money can be created from thin air once the
system is initialized. And to keep things simple, I won't actually be using a crypto question but a simple question.

Now, we want to make a transaction from user 1 to user 2. Let's say we want to move 25 coins. To do this, first, we have to solve the crypto question. In this case the question is 100 - 0 + x = 25 and x becomes -75. So, we enter -75 to our system and start creating the next entry.
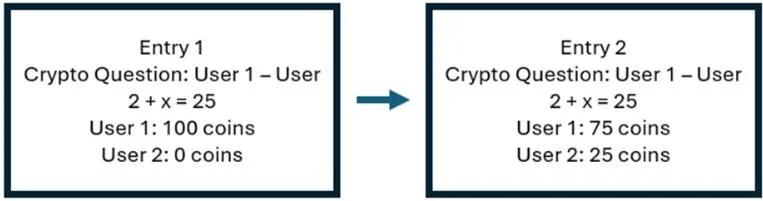
Next time we want to add an entry, we have to solve the crypto questions from the second entry. So, let's say we want to transfer another 10 coins from user 1 to user 2. Now, the crypto question becomes 75 - 25 + x = 25 and x comes out to be -25. So, we enter that.

Now, let's say that the user 2 wants to commit some fraud and add some extra money into his account. As we can see, we can only add data to the next entry and there are only 100 coins in this system. As long as user 1 doesn't transfer any, he can't get more. So, his only option is to go back to the beginning (the initialization) and add himself some money. Let's say he adds 50 coins. But this creates an issue.
Each one of these chains are connected. So, if you want to change the first chain link, you have to change the whole chain because the crypto question you are solving depends on the amounts each user has, i.e. the previous step.

So, to create this chain, he needs to solve 2 crypto questions in a row, and replace the original chain. First, he needs to solve 100-50+x = 25 to create entry 2, and then he needs to solve 75-75+x=25 to create entry 3.
As the chain grows in size, it gets increasingly harder to edit any part of the chain since you have to replace the whole chain instead of the parts.
Third technology for security is a distributed system. Basically, this chain lives in more than a single computer, and for each entry or edit, over 50% of computers have to agree that it is a valid transaction.
Sounds pretty safe so far, right?
No.
Remember the crypto miners of 2020? They were basically editing the whole chain to add new coins. As it turns out, if you have enough computers, you can hack this. It's not your own government printing money anymore, it is a random dude in China or Saudi Arabia with a rack of computers doing it.
Now that we know BlockChain fails to deliver on all of its promises, what about its usefulness in records management? It still is a pretty safe system.
Unfortunately, safety comes at a massive cost. Cryptography questions are insanely expensive to solve. Just check the cost of a bitcoin. That's how computationally expensive these questions are.
It also is a horrible system for data management. Editing or deletions are next to impossible. Furthermore, you can't search the BlockChain ledger easily. Let's say you want to keep your audits in this ledger and want to find every healthcare record that was deleted.
All you have is a list of events in chronological order. To find each healthcare records, you need to look at every single entry, one by one and ask the question, is this a healthcare records audit report?
Do you still believe in BlockChain?
Regulations will save our industry
By January 2025, the cumulative total of GDPR fines has reached approximately €5.88 billion. The fines still didn't stop META from collecting biometric data in Texas and getting penalized another $1.4 billion.
The privacy regulations were supposed to help us be safe and improve records management. It was the talk of the town in ARMA circles from 2016, and is still seen as a way to get our field the value it deserves.
Yet, they don't work.
The fines themselves are minor compared to the money made by breaching the laws. META has been penalized a total of $2.7 billion dollars over 2 years. In the same time, they made over $100
billion in profit by selling off your personal data.
Same pattern can be seen in SEC, seemingly built to enforce proper records keeping. In 2022, 16 Wall-Street banks were fined $1.1 billion for failing to capture off channel communications, namely WhatsApp messages. (Thanks Meta)
Their response .......... do nothing. As if to say, "We made more money insider trading and playing with your future than the measly fine of $1.1 billion."
Fines are seen as part of business usual, not as regulations to be followed. The total cost of the fines are too small and simply can be passed down to customers as in more ads on Facebook, Instagram and WhatsApp.
So, how do we change business usual?
There is the obvious. Improve regulations and actually make the fines hurt. But my friend Ramesh K V has a better idea. Hall of shame.
Each business who have been fined has to put a pop-up on their website that stays for at least 30 seconds. You got fined by SEC, you put "We used your money to commit fraud and made billions by risking your economic future. Do you still want to bank with us? Yes or No"
To read more on how we can make regulations work, check my blog Regulations Won't Help Your Records Program
Trash Data in, Trash AI Out
You probably heard this a hundred times from vendors. But how much of it is true?
Data is one of three levers AI scientists can pull. There is also Model and Scale/Compute, and sometimes they matter more than the data. The most famous example of quality data misleading analysts is from the 2nd world war where air warfare was introduced.
During 2nd WW, British air forces were losing one too many planes. So, they gathered a bunch of government analyst to find a solution. They collected the locations of all the bullet holes in the planes. The results were striking, pictured below.
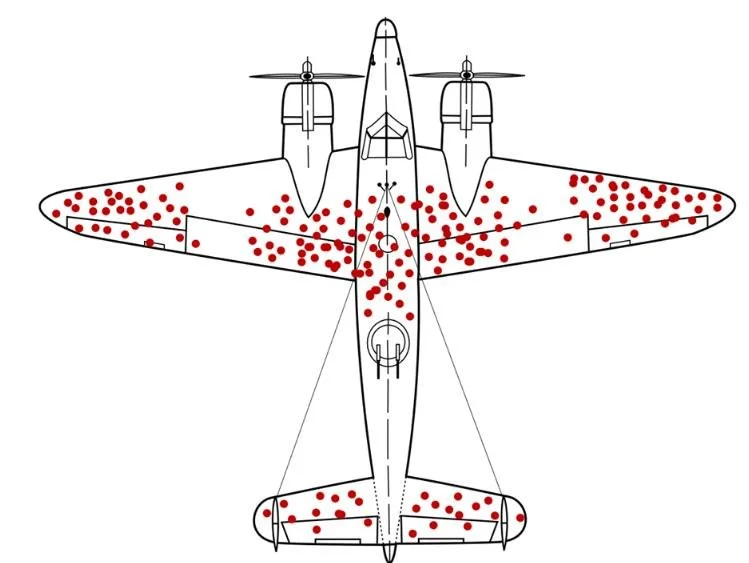
The planes were most frequently shot at the wings and the core of the plane. So, they decided to reinforce those parts to bring more soldiers and planes back home.
Sounds perfect, but the worst mistake of all times!
The data was gathered from the planes that returned. So, if you got shot in these areas, you actually made the trip back. It took a smart statistician to point out that we should be reinforcing the white parts, not the red dots.
Same data, different thinking patterns. This is why your model matters. The model is the thinker, and if you use the wrong one, your quality data means jack.
While we are at it, here are 2 other funny examples.
Imagine you are doing a digitization project and decide to tag PII while digitizing. Goal is to detect numbers automatically and if they look like a social security number or a phone number, you tag it.
So, you go back home, learn how to create an AI. You feed it 70,000 hand written numbers. You deploy the AI.
Surprise! Every document has 20,000 pieces of PII. But how?
Machine learning algorithms are paranoid. Your algorithm only knows numbers, so wherever it looks, it sees numbers. To a man with a hammer, everything is a nail.
So, Bob Boby Bob turns into 806 8069 806. Which looks a lot like an American Social Security Number. If you want to test this out and see for yourself, here is a free AI tool that was trained on exactly 70,000 hand written numbers.
Arbitrarily choosing what is good data and what is bad data is never a good plan. This is why the average AI scientist makes $150,000 a year.
Most recent example where data doesn't matter at all is ChatGPT.
It was trained on the internet where almost all data is trash. Yet it works? How?
Because of model strength and the sheer scale of the project. GPT's goal is not to learn a set of facts, but to replicate human speech patterns. By copying human speech, it achieves near human reasoning. Therefore, the tool can learn both from good data and bad data since both contain human reasoning. It can generalize the reasoning without getting stuck on the factual details and whether the information is good or bad.
Trash data in, trash AI out is definitely correct. But what counts as good data is hard to detect and depends on many other factors. We need to be managing all our information, not just what we deem as good, especially now more than ever.
For reference, below is what each use case cares the most about.

Too much data to manage
This one sends me bonkers.
Yes, there is way too much data. Yes, it is growing faster and faster.
No, too much is not an excuse, it's a choice.
"Too much data" becomes a problem under 2 circumstances, neglect and perfectionism. Neglect happens more frequently, especially in our sister field eDiscovery.
This is changing slowly with the addition of proper Information Governance to the EDRM model.
Yet it's not changing fast enough, mostly due to excuses.
Ask yourself and your company. How many archives do we have? Do we ever delete older data? If so, how much of it do we delete?
And you will quickly realize data is rarely deleted. So, if we are going to keep this data for eternity due to neglect, why not manage it properly?
You don't even need a vendor's help. All you need is an IT guy and 2 software engineers. Move everything old into secondary or tertiary storage. Use Lucene(free to use) to index all of these documents and make them searchable. Keep the index in primary storage for fast search.
You will save millions of dollars in storage costs, and when you need a document, you can find it instantly.
Perfectionism is the second enemy. It happens when an organization obsesses over defensibility and inadvertently make themselves less defensible.
Ask yourself, if SEC regulated banks that control all of our economic futures can delete all of their documents after 7 years, why are we not? If it's not a record, it must go.
This idea usually worries people. What if there are records in these unmanaged data sources?
What if we get into trouble for deleting them? I ask back, if we never go looking for them, if we never declare them as records, are they really records? If we can't ever find them because there is too much data and the server times out each time we run a search, are they not already gone? Because that's what will happen eventually, server time outs.
Perfectionism is the enemy of the good. Don't let it get you.
Only if .....
You heard it a million times before.
Only if people read the records policy. Only if people cared about records. Only if we had a coordinators network. Only if we had a culture of records management. Only if people paid attention to records trainings. Only if... Only if...
I am a firm believer in records policies, strong execution, and change management but unfortunately none seem to work.
According to a 2017 study by Deloitte, 91% of consumers accept the terms and conditions without reading them. If you are hopeful that corporate workers are better, prep for a surprise. 66% of corporate workers don't read their employee handbook.
If your peers don't read the most important policy book - the employee handbook - how can we expect them to read records management policies? And furthermore, how can we expect them to follow through with it?
Are Records Policies Enough, and if not, what do we do?
Let's be honest. It takes 4 hours a week for end users to classify their records. And they don't do it. That leaves us with one of two choices. Hire a records manager for every 10 business users, or find a way to change our culture and supplement our work with technology.
As most of us are one many armies, our only option is to change the culture. And that's where "only if" comes into play. And it doesn't work good enough just by itself.
Don't get me wrong, I'm a change champion. I love change and I wrote about how you can make change work for you in my recent blog Make the most of Records Management.
But humans can change only so much, and it takes a while. Whereas technology changes fast, there is a new software update to SharePoint Online every month. If our only option is change
management, we will never keep up with the pace of technology.
If we need to battle technology, we need to battle it back with technology itself, combined with change management.
Like this content and want to see more?
Subscribe to my Newsletter Here.